

Base tool that answers general questi-ons without using any external tools.
Solving complex reasoning tasks may involve visual understanding, domain knowledge retrieval, numerical calculation, and multi-step reasoning. Existing methods augment large language models (LLMs) with external tools but are restricted to specialized domains, limited tool types, or require additional training data.
We introduce OctoTools, a training-free, user-friendly, and easily extensible open-source agentic framework designed to tackle complex reasoning across diverse domains. OctoTools introduces standardized tool cards to encapsulate tool functionality, a planner for both high-level and low-level planning, and an executor to carry out tool usage. We validate OctoTools’ generality across 16 diverse tasks (including MathVista, MMLU-Pro, MedQA, and GAIA-Text), achieving substantial average accuracy gains of 9.3% over GPT-4o. Furthermore, OctoTools also outperforms AutoGen, GPT-Functions and LangChain by up to 10.6% when given the same set of tools. Through comprehensive analysis and ablations, OctoTools demonstrates advantages in task planning, effective tool usage, and multi-step problem solving.
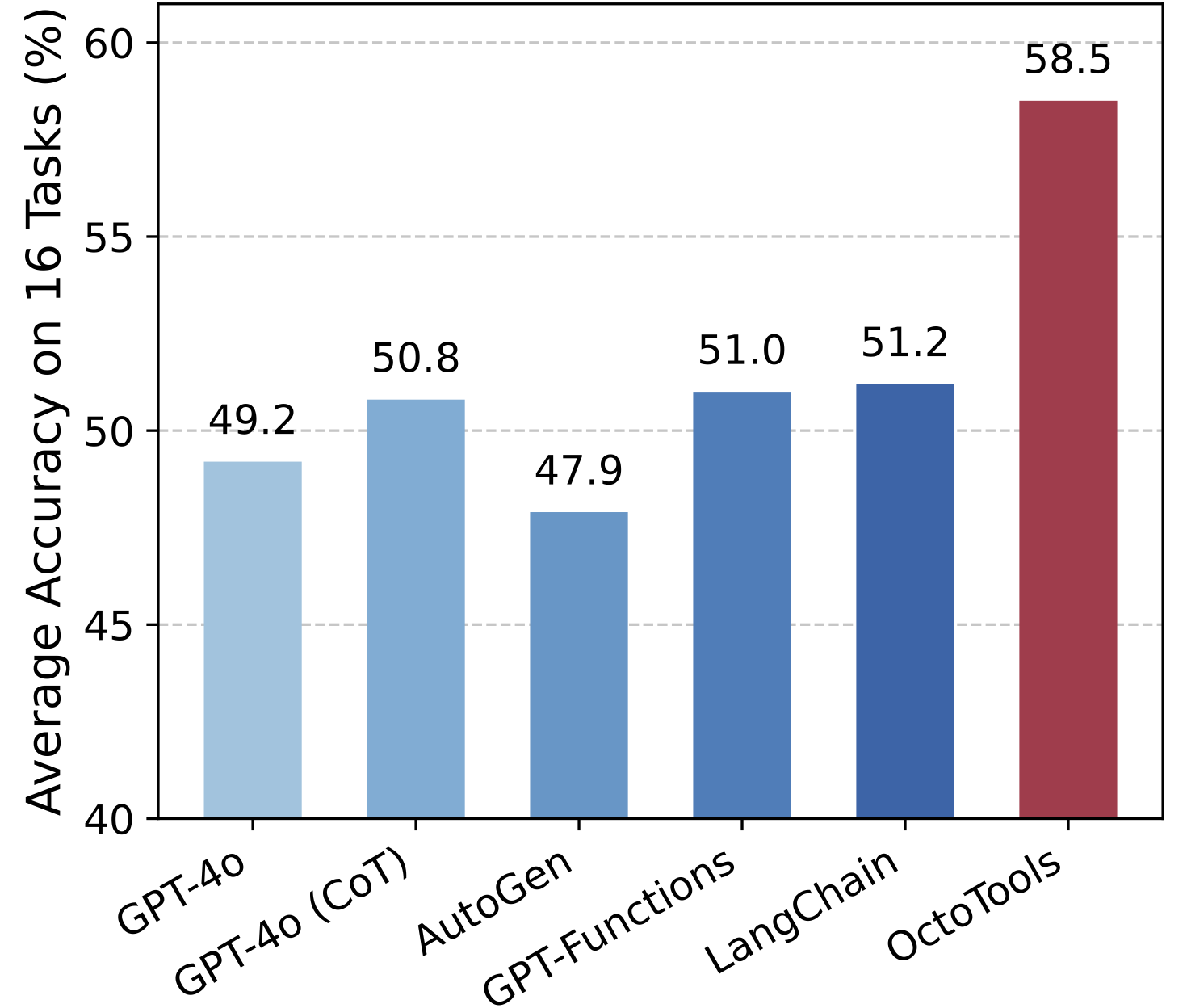
Performance comparison across 16 diverse tasks. OctoTools achieves substantial improvements over GPT-4o and other frameworks including AutoGen, GPT-Functions, and LangChain when given access to the same set of tools.
Our framework provides a diverse set of tools to handle different types of tasks. Here are some key tools in our toolbox:
Base tool that answers general questi-ons without using any external tools.
Generate a caption for a given image with a text prompt.
Locate and zoom in relevant quarter patches in an image given a question.
Detect text with coordinates and confi-dence scores in an image by EasyOCR.
Detect objects in an image using the Grounding DINO model.
Search Wikipedia for relevant informa-tion based on a given query.
Search the Google website for relevant information based on a given query.
Visit the given URL and extract all text from that page.
Generate and execute Python code snippets for basic calculations.
Search arXiv for the latest literature based on a given query.
Search PubMed for the latest literature based on a given query.
Search the latest news articles from the Nature website.
Classify H&E-stained pathology images into one of the given options.
⚒️ More Tools ...
More tools can be added!
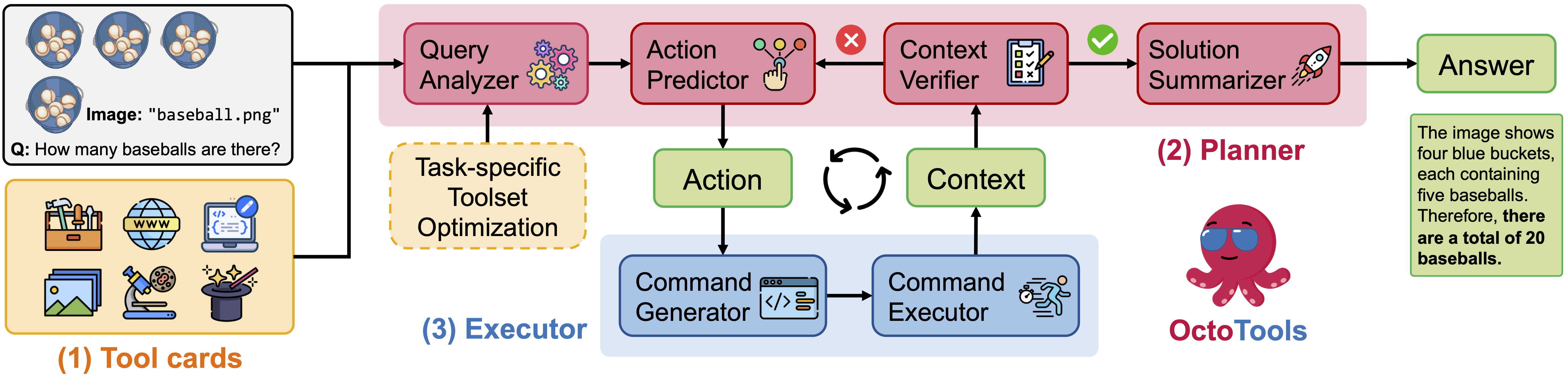
We propose OctoTools, an open-source, versatile, and user-friendly agent-toolbox framework for complex reasoning tasks. Given a user query $q \in \mathcal{Q}$ and a pretrained language model $\text{LLM}_\theta(\cdot)$, a naive approach would generate an output directly as $y \sim \text{LLM}_\theta(q)$, providing a single-step response. In contrast, our OctoTools framework introduces a structured, multi-step process that leverages external tools to tackle queries effectively.
Specifically, OctoTools contains a set of tools $\mathcal{D} = \{d_i\}_{i=1}^n$ and associated metadata $\mathcal{M} = \{m_i\}_{i=1}^n$, where $n$ is the number of available tools. Given a query, a planner (based on a language model) first generates a tentative plan from a high-level perspective, indicating how these tools can be used to address the query, which forms the initial context $s_0$. From this plan, the planner determines the initial action $a_1$ for tool usage, specifying which tool $d_1$ to use, the relevant context, and a sub-goal. An executor (also powered by a language model) then converts the planner's text-based action $a_1$ into a machine-executable command $o_t$, which is run to obtain intermediate results $r_1$. These results, along with the original action, update the context to $s_1 := (a_1, o_1, r_1)$. This process constitutes one step in our framework.
This process repeats, with the planner iteratively refining its actions based on the evolving context until it either finds a complete solution or inference limits (e.g., time or steps) are reached. After $T$ steps, the framework produces a full trajectory $(s_0, s_1, \dots, s_T)$, which is stored in a structured manner in the context. The planner then uses this trajectory to generate the final solution to the original query.
To sum up, OctoTools provides a robust and effective framework for solving complex tasks through sub-goal decomposition and systematical tool usage. Standardized tool cards encapsulate functionality , the planner orchestrates both high-level and low-level task planning, and the executor instantiates tool calls for each sub-goal.
The OctoTools toolbox contains a diverse set of tools covering different modalities and skills. By leveraging structured tool cards and robust planning capabilities, OctoTools demonstrates strong generality when all available tools are enabled across different tasks. However, when a small set of validation examples are available for a task, configuring a task-specific subset of tools can further enhance efficiency and effectiveness.
To this end, we propose an automated algorithm to optimize the toolset configuration for each task. Given $n$ available tools in the toolbox, the total number of possible subsets is $O(2^n)$, which is prohibitively large. To make this tractable, we employ a greedy search strategy that reduces the complexity to $O(n)$. Our approach proceeds in three stages.

To demonstrate the generality of our OctoTools framework, we conduct comprehensive evaluations on 16 diverse benchmarks spanning two modalities, five domains, and four reasoning types. These benchmarks encompass a wide range of complex reasoning tasks, including visual understanding, numerical calculation, knowledge retrieval, and multi-step reasoning.
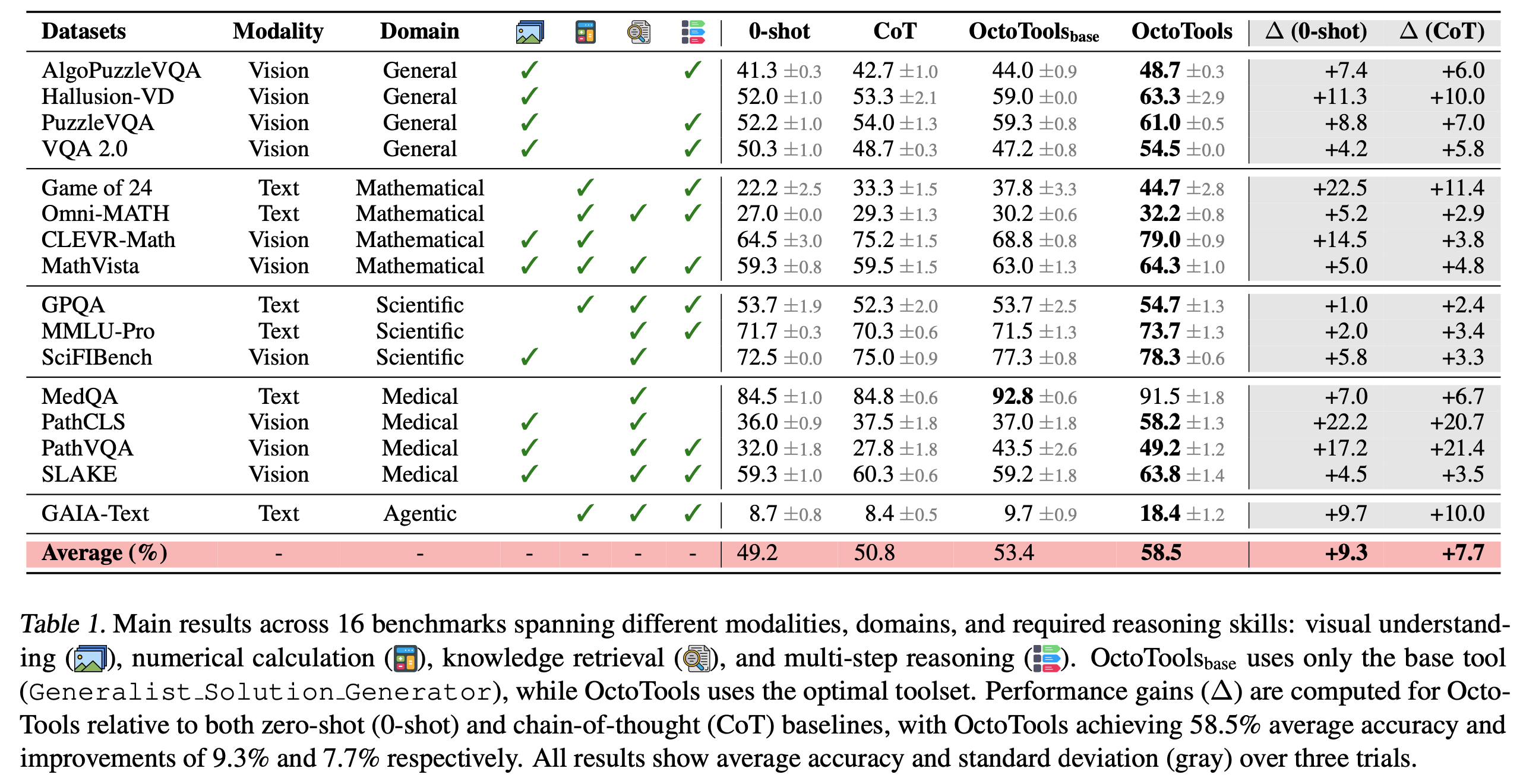
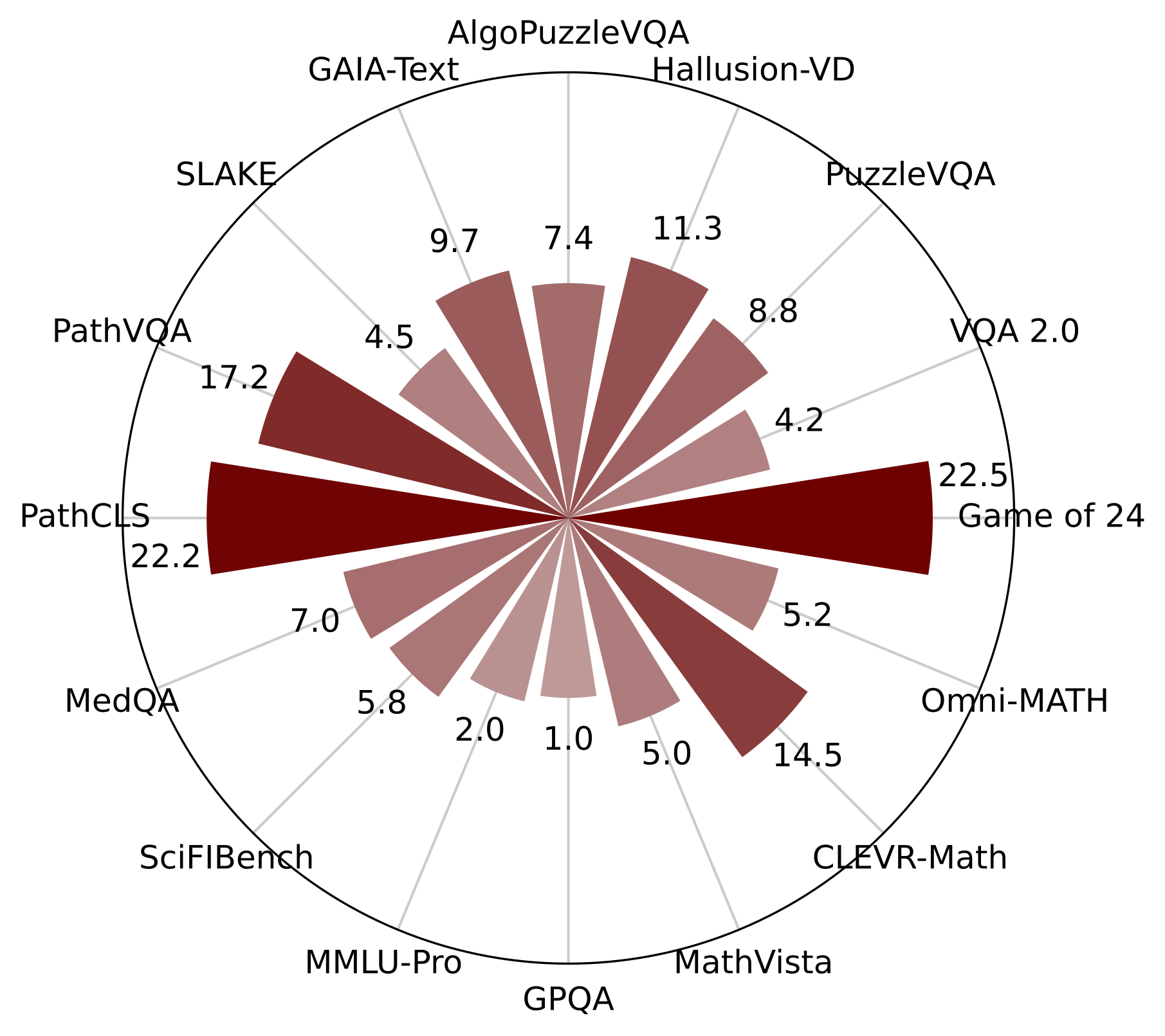
Performance gains across different benchmarks from our OctoTools framework over the base GPT-4o model.
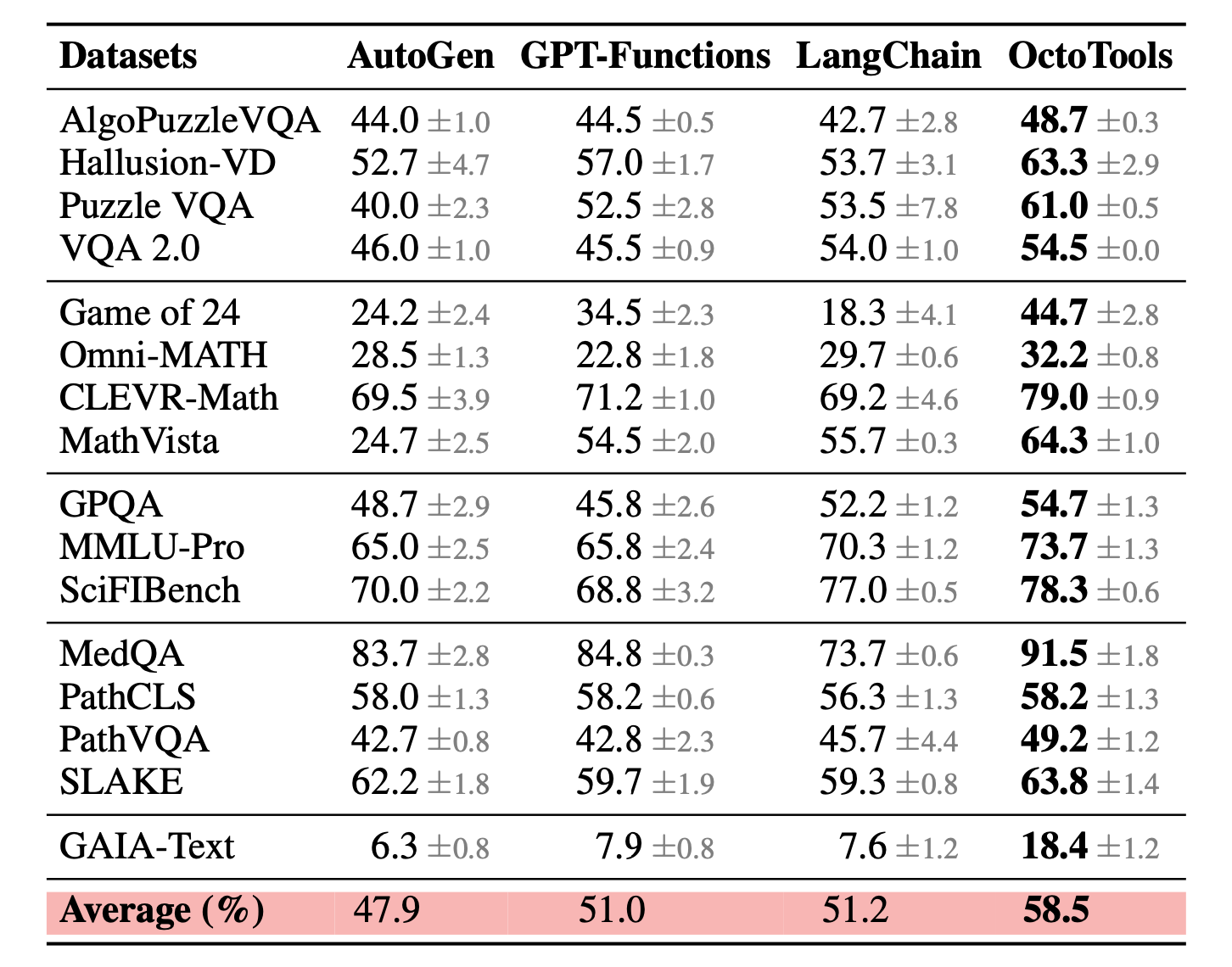
Comparison with other agent frameworks using the same underlying toolbox. OctoTools achieves superior performance with an average accuracy of 58.5%, outperforming the next best baseline by 7.3%. Results are averaged over three trials.
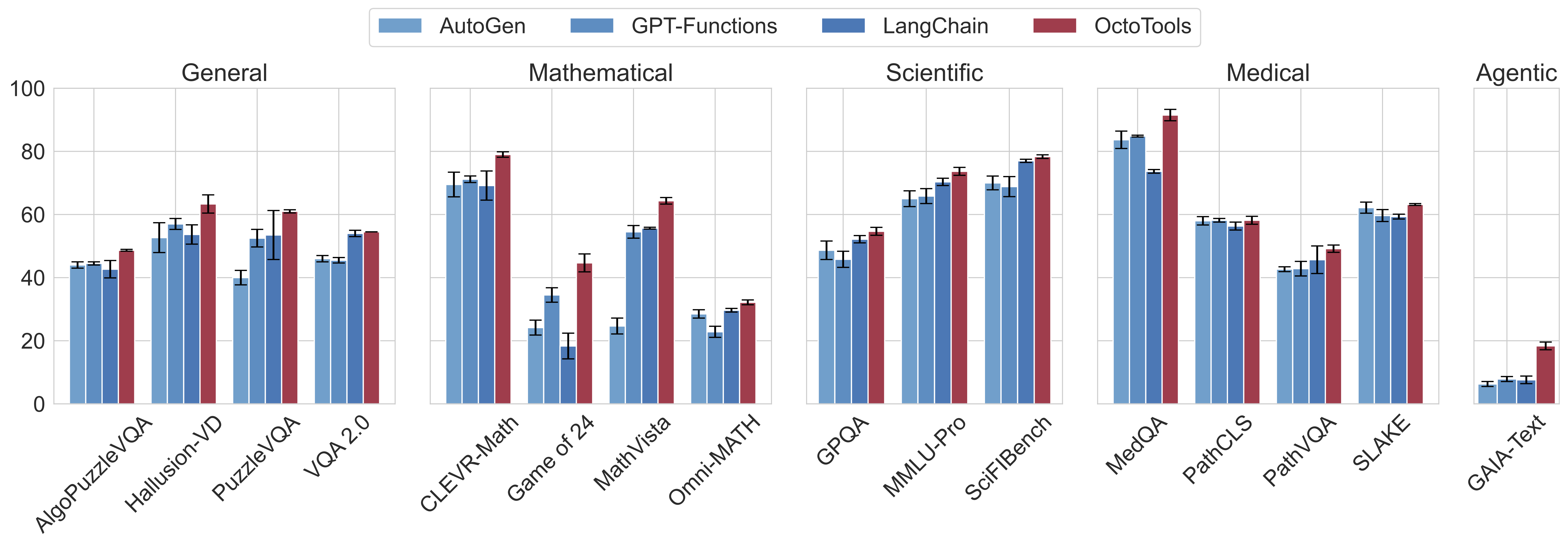
Performance ours vs. other agents. Our framework consistently outperforms agent baselines across all benchmarks. Bar values represent accuracy and error bars represent standard deviation.

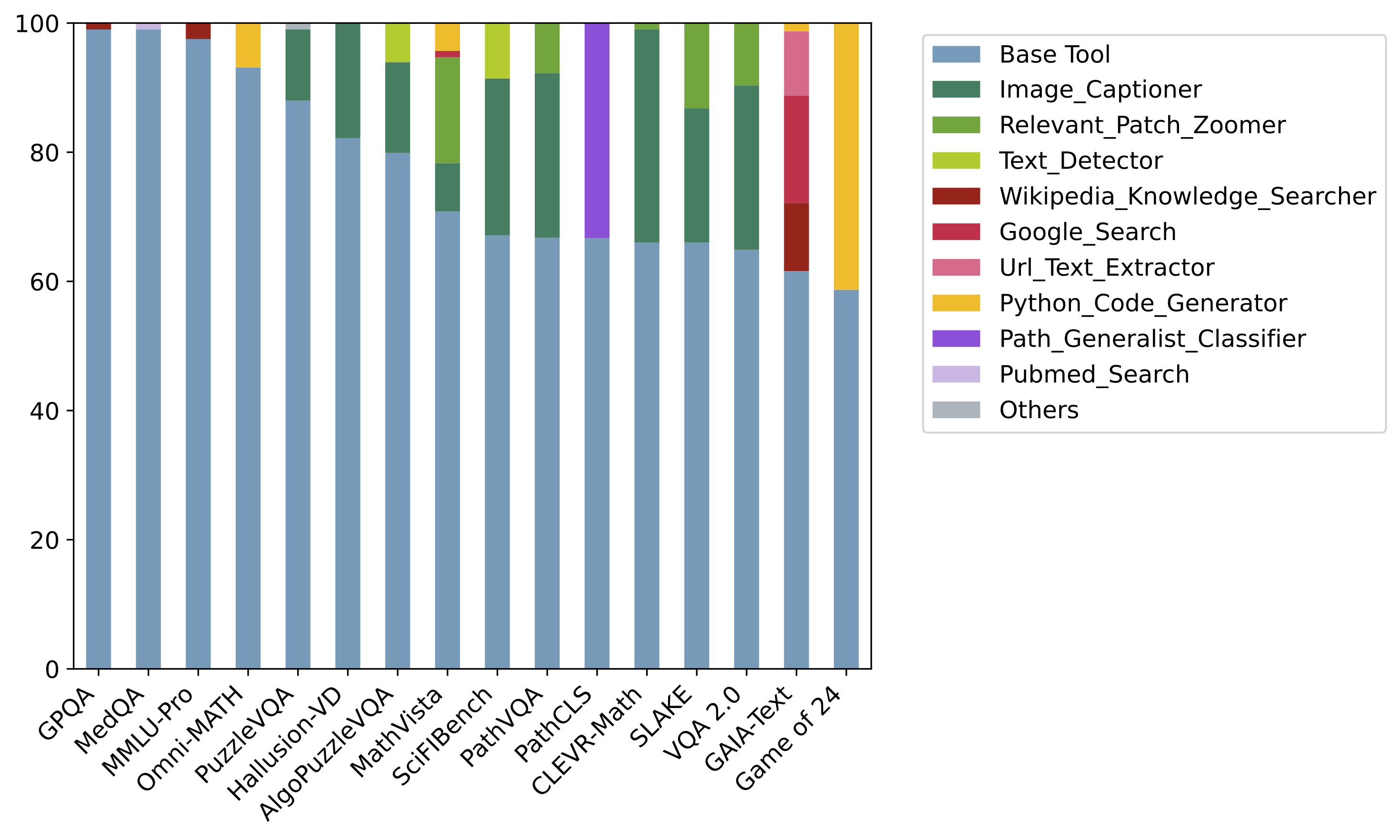
a. Tool usage distribution in our OctoTools framework and agent baselines by averaging results from 16 tasks. b. Tool usage distribution across 16 tasks in OctoTools. OctoTools takes advantage of different external tools to address task-specific challenges.
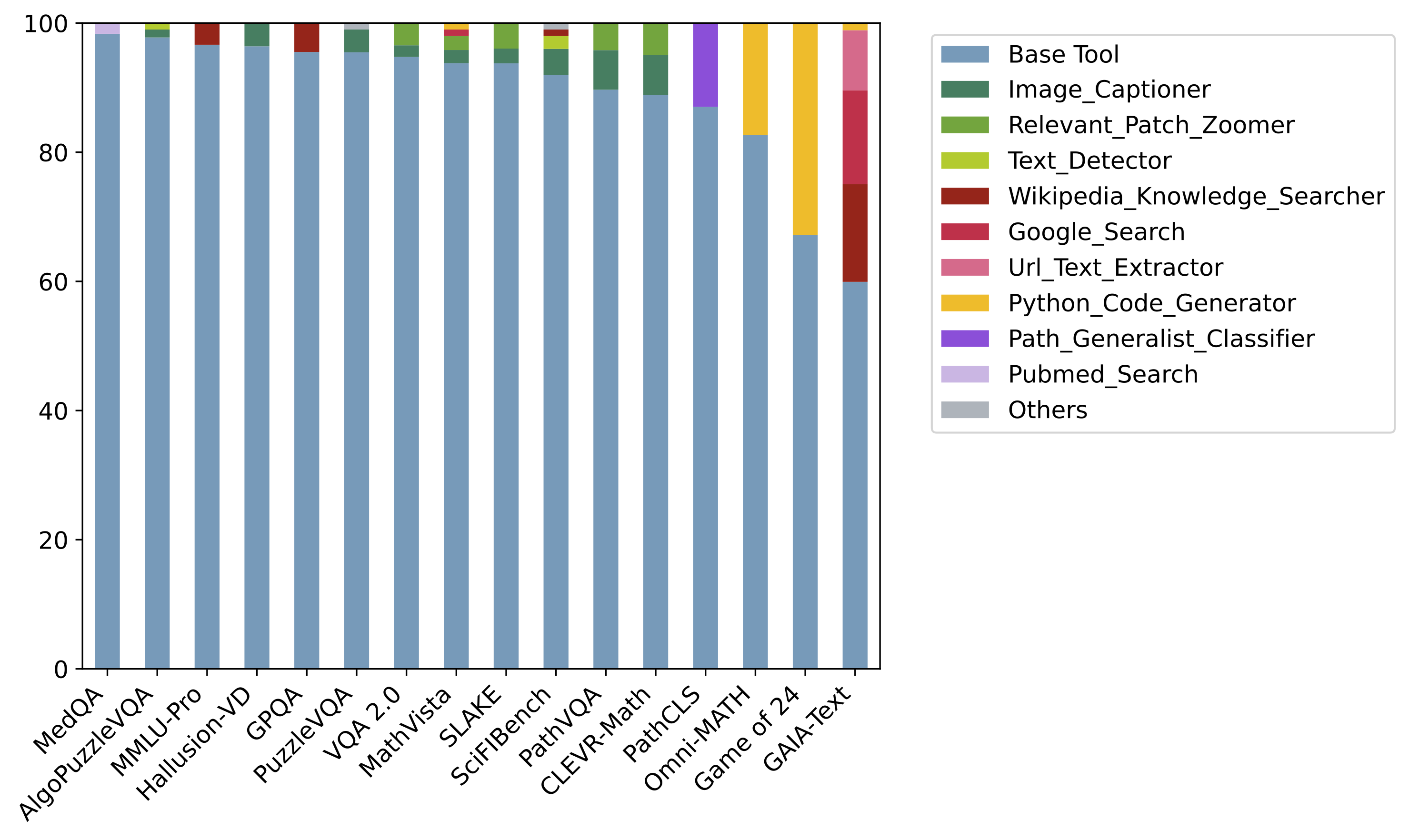
Distribution of tools usage. Frequency of tools used by the AutoGen agent for each benchmark.
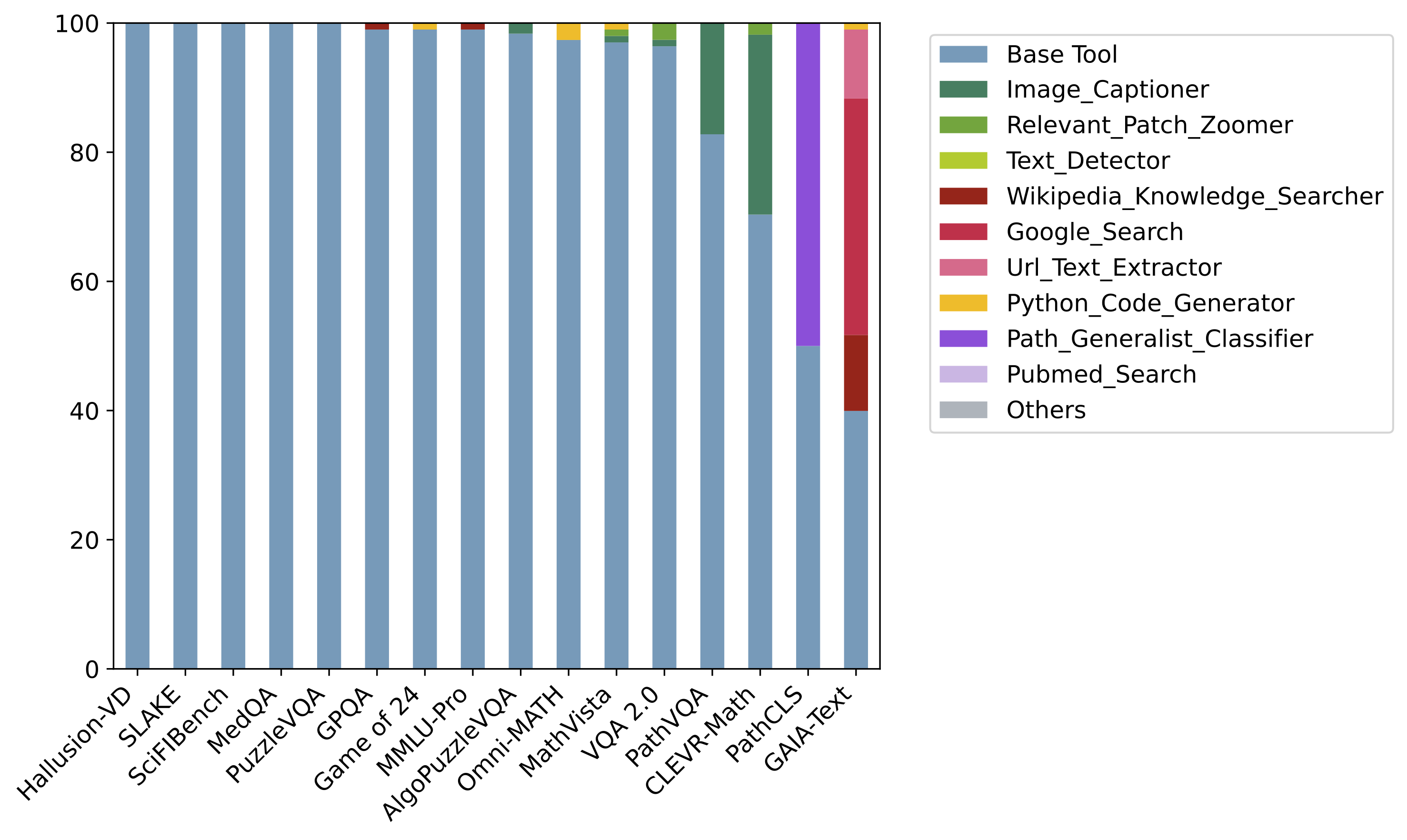
Distribution of tools usage. Frequency of tools used by the GPT-Functions agent for each benchmark.
Distribution of tools usage. Frequency of tools used by the LangChain agent for each benchmark.
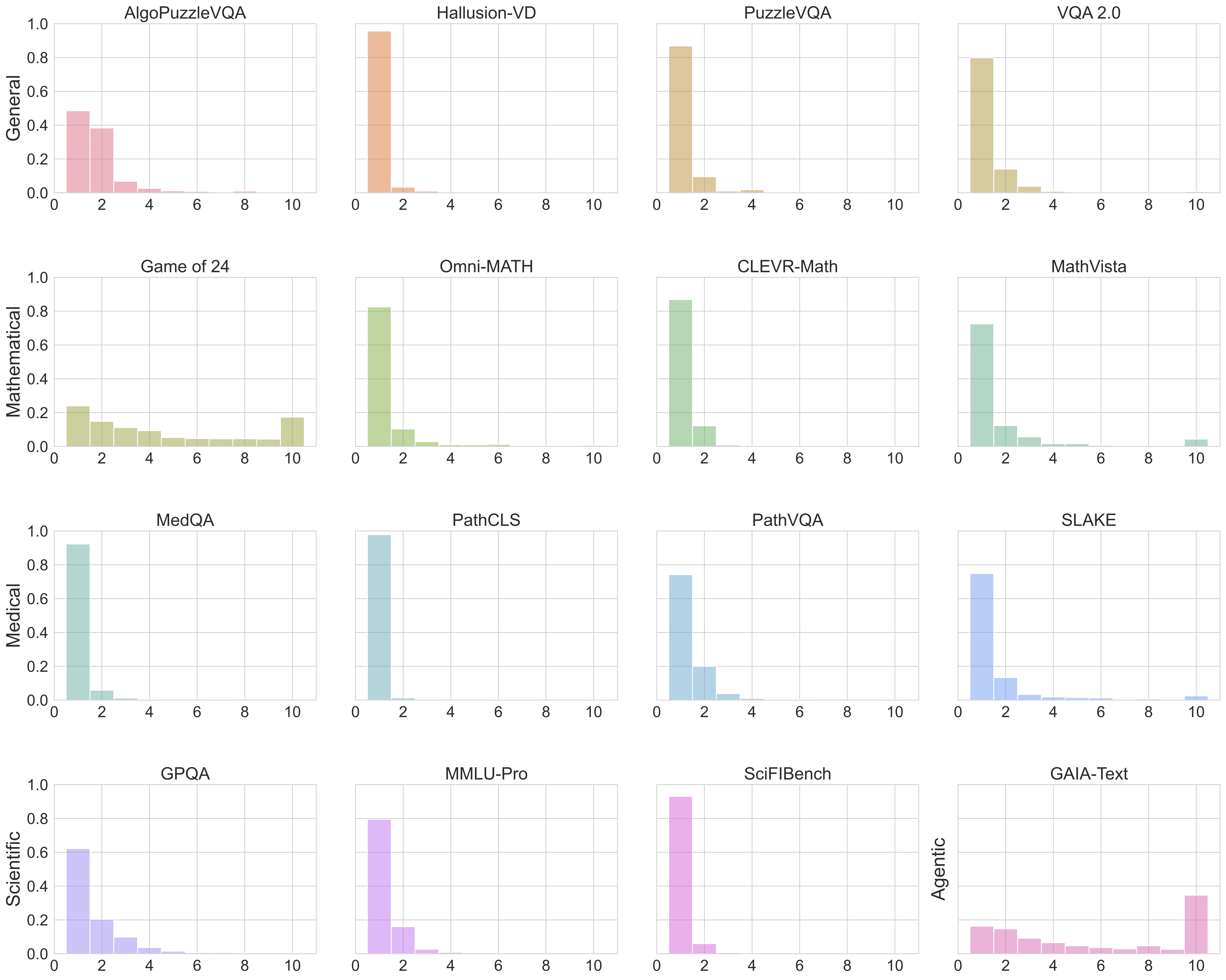
Distribution of number of steps used.
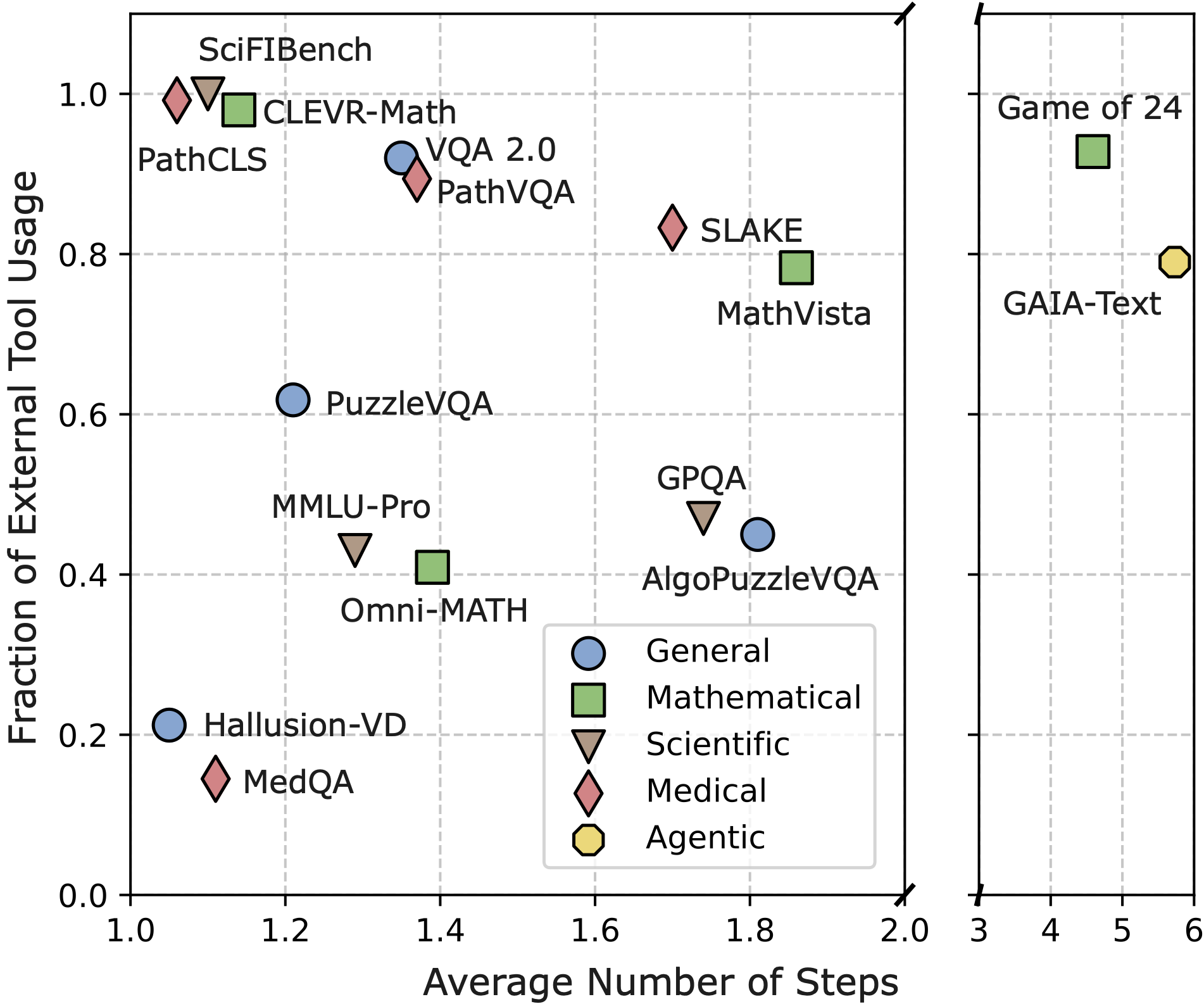
Benchmark distribution across average number of steps and fraction of external tool usage (tools that exclude the base tool Generalist_Solution_Generator) in OctoTools.
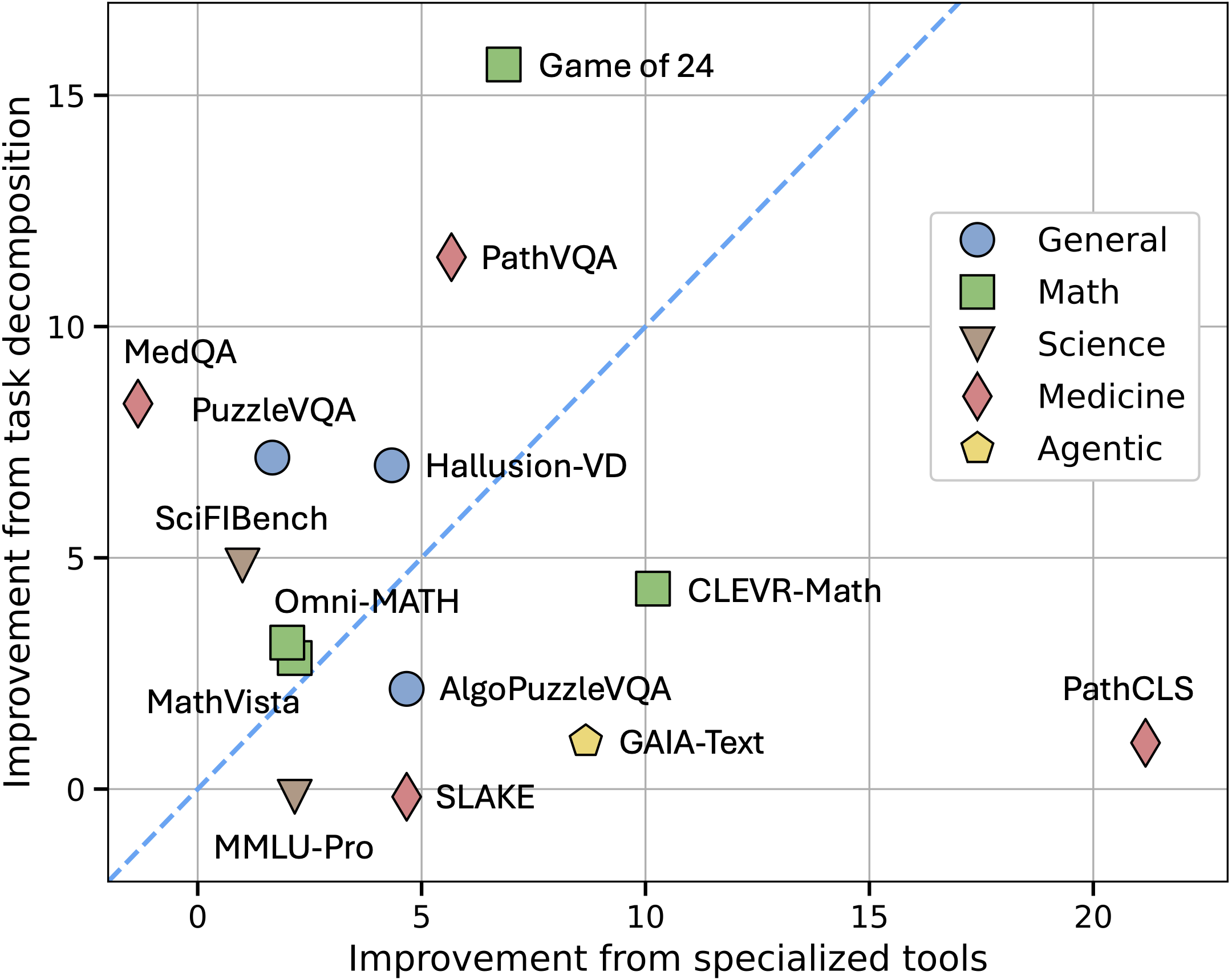
Benchmark distribution across two dimensions. Tasks that show high improvement from task decomposition likely require multi-step reasoning, while tasks that show high improvement from specialized tools likely require specialized skills.
We further explore several factors that affect OctoTools's performance, using a validation set of 100 samples.
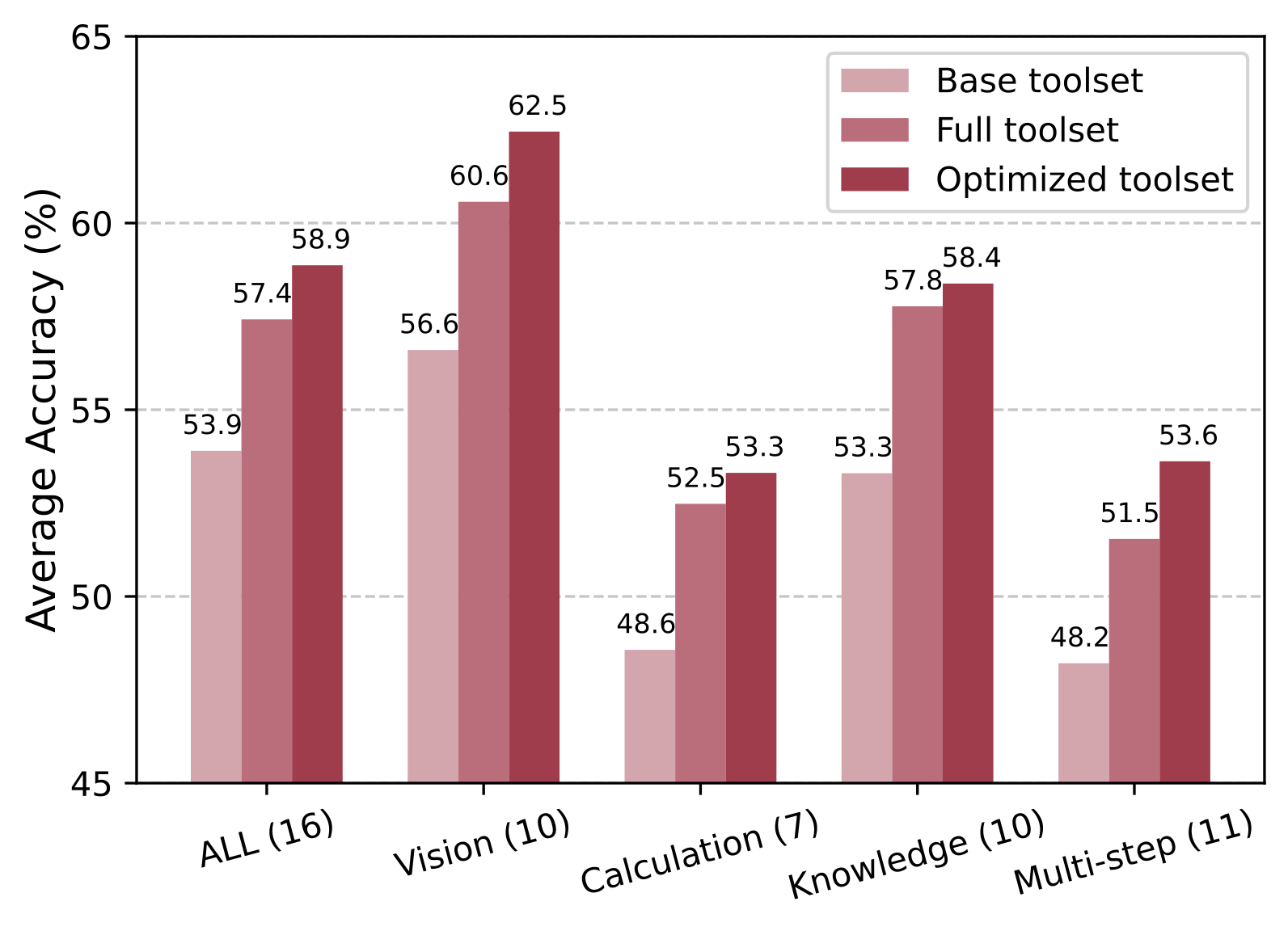
Performance under three toolset strategies in OctoTools across all 16 tasks and various categories (the number in parentheses indicates the number of tasks in each category).
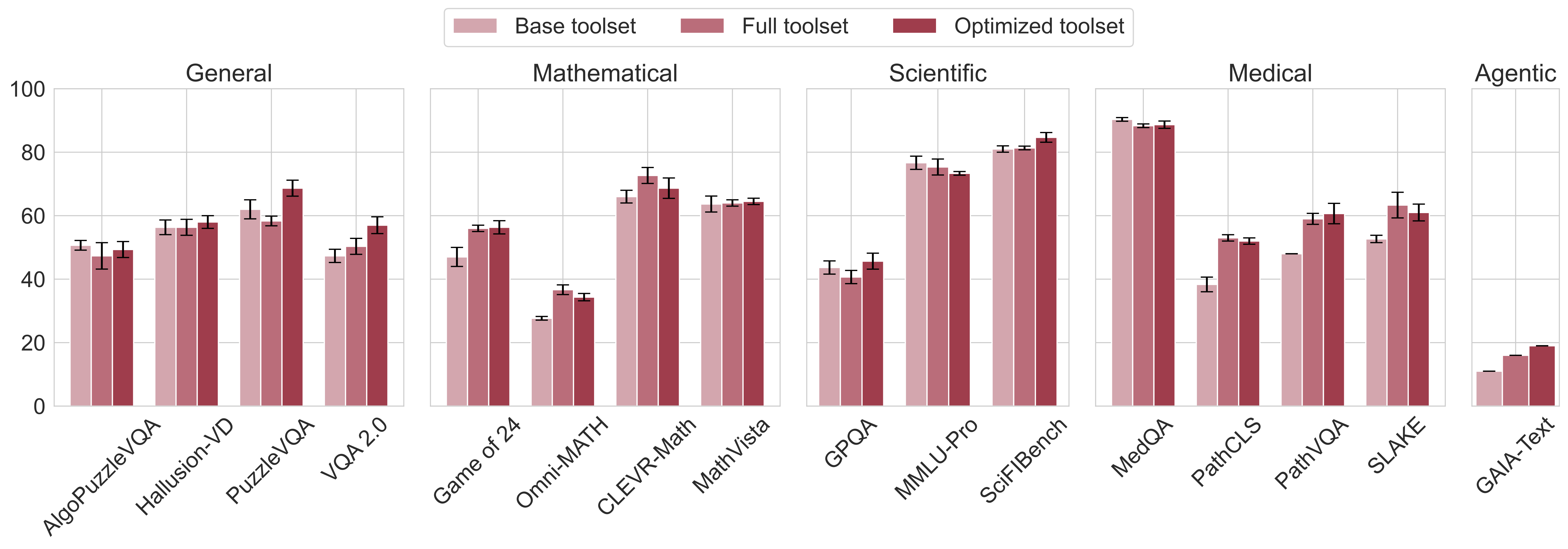
Performance with vs. without tool selection. While toolset optimization increases performance over using the full toolset in most tasks, even without it, our framework achieves similar performance by naively enabling all possible tools. Bar values represent accuracy and error bars represent standard deviation.
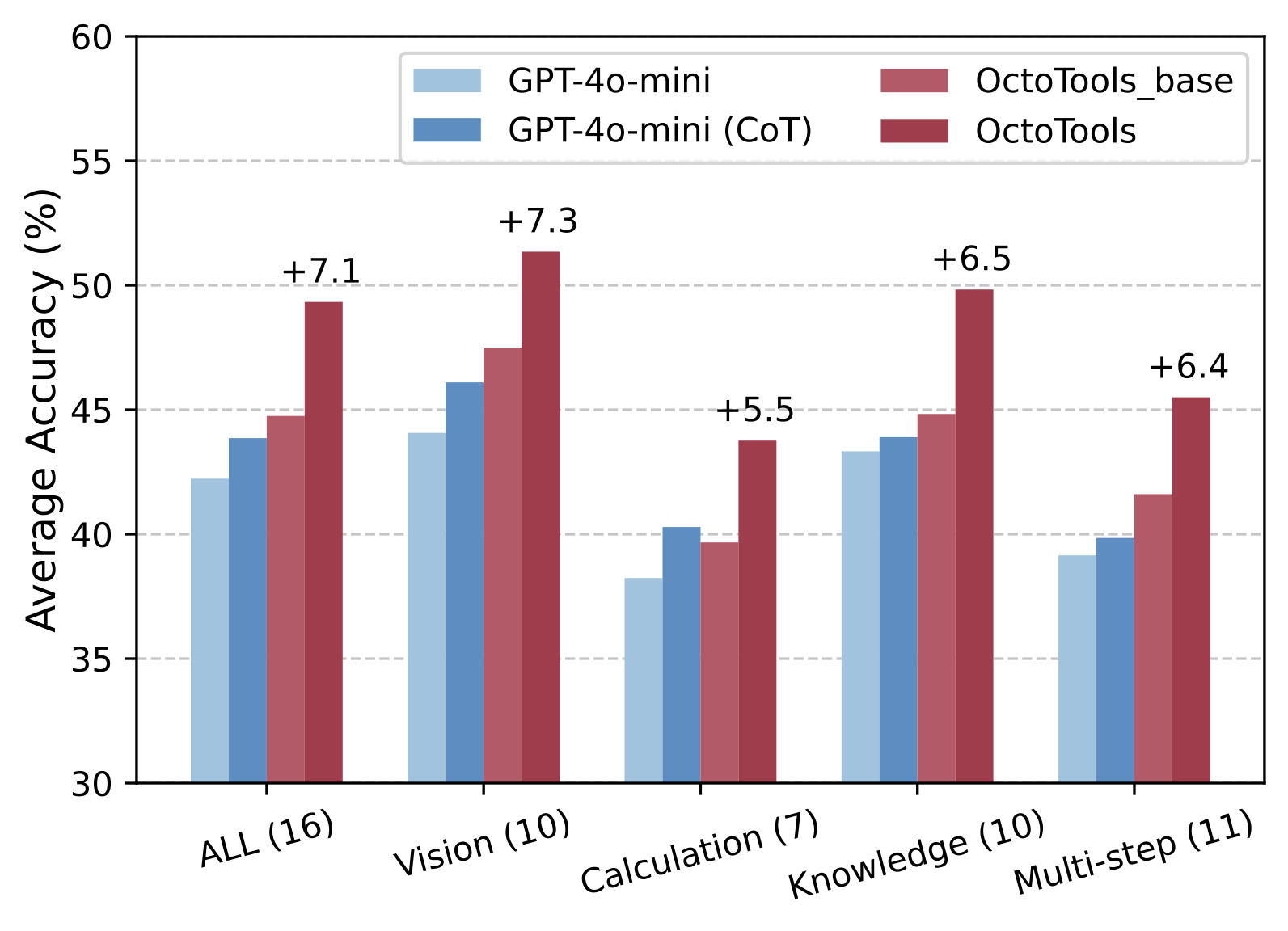
Performance of OctoTools on 16 tasks and various categories using a weaker LLM, GPT-4o-mini, as the base engine. OctoToolsbase is the configuration in which only the base Generalist_Solution_Generator tool is enabled. The number in parentheses indicates the number of tasks in each category.
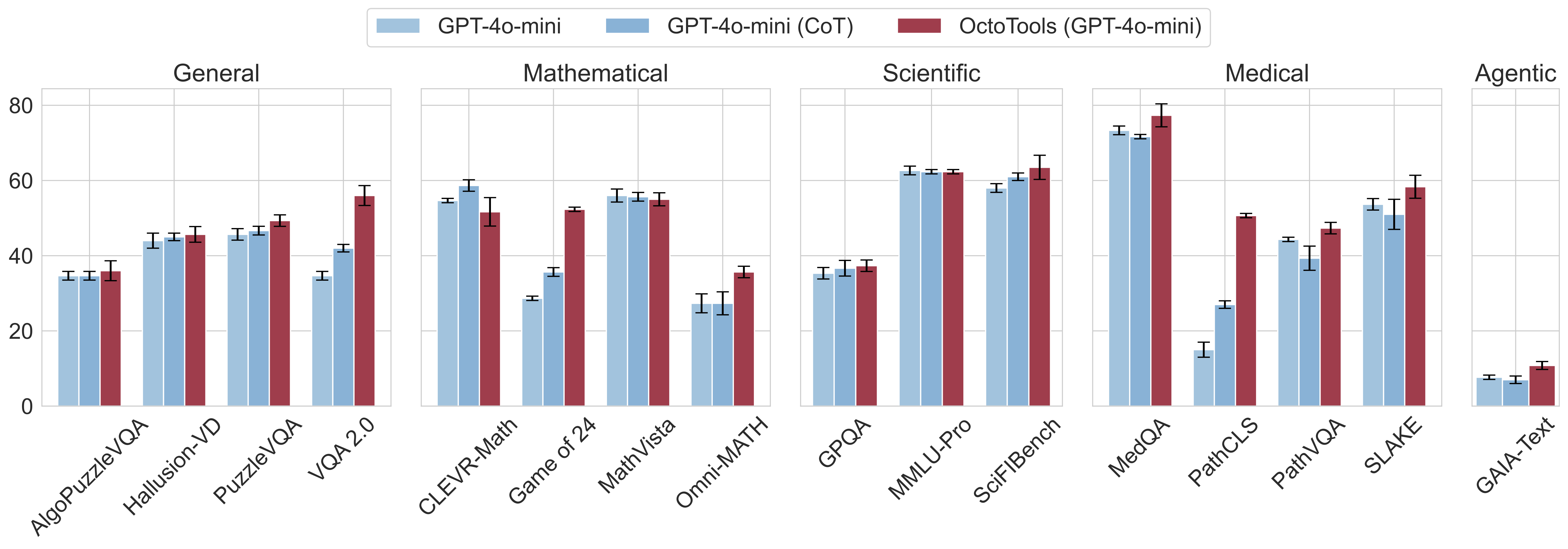
Performance ours vs. other agents. Our framework consistently outperforms agent baselines across all benchmarks. Bar values represent accuracy and error bars represent standard deviation.
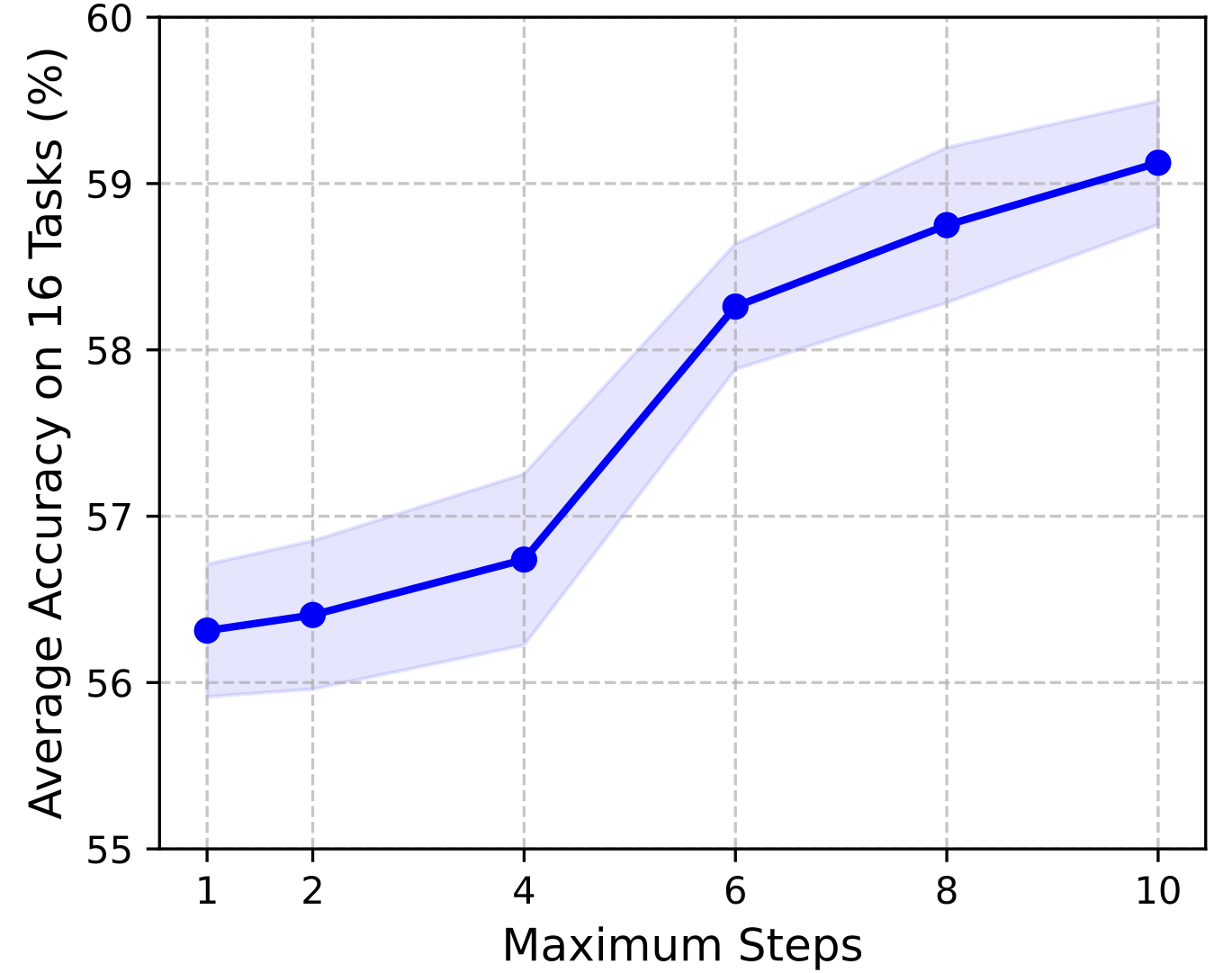
Average accuracy across 16 benchmarks with respect to maximum allowed reasoning steps in OctoTools. Overall, performance tends to improve as the maxmum number of steps increases, highlighting the benefit of longer chains of multi-step reasoning.
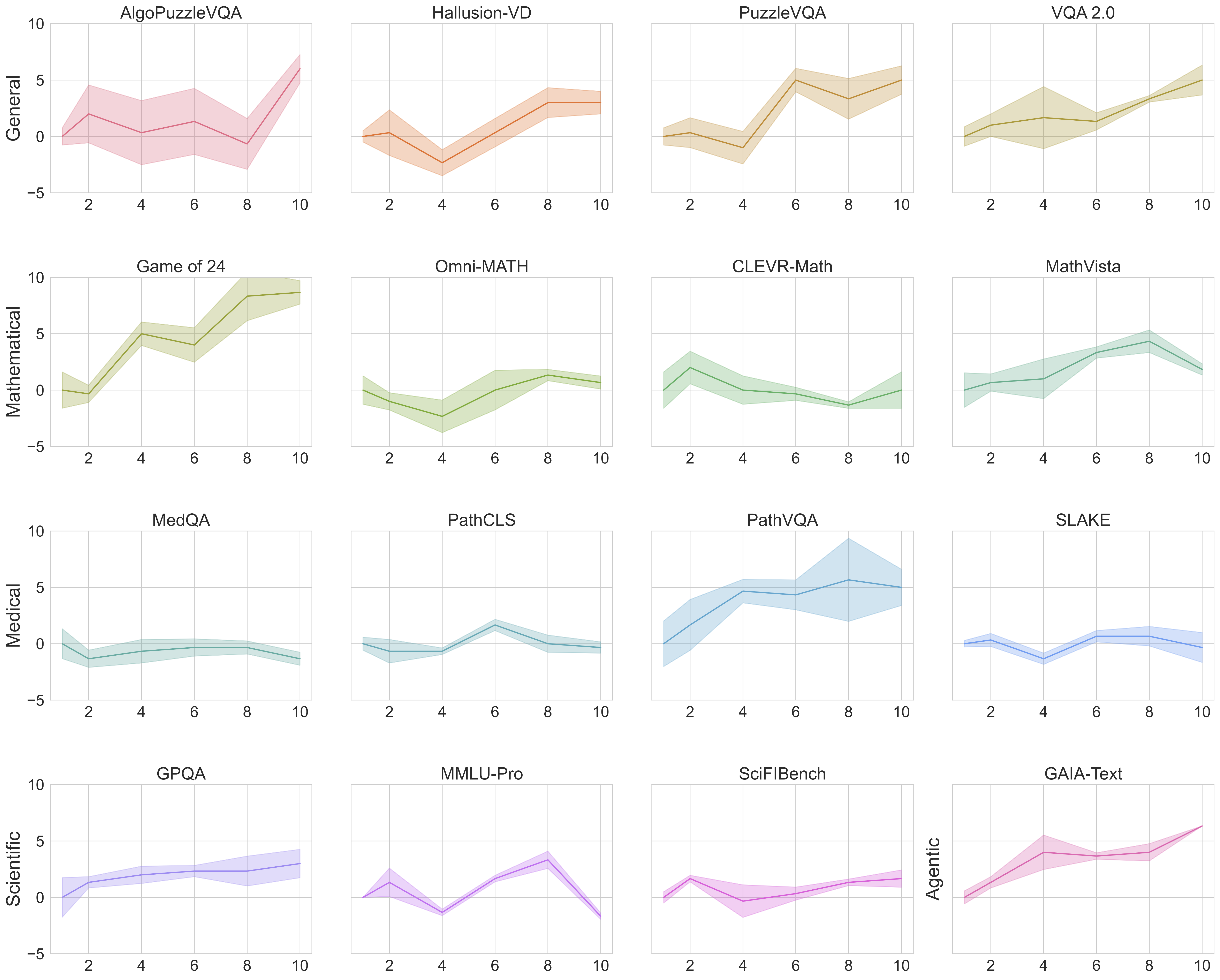
Accuracy vs number of maximum steps. The change in accuracy from a maximum step of 1 is plotted. Most benchmarks improve in performance with the number of allowed steps.
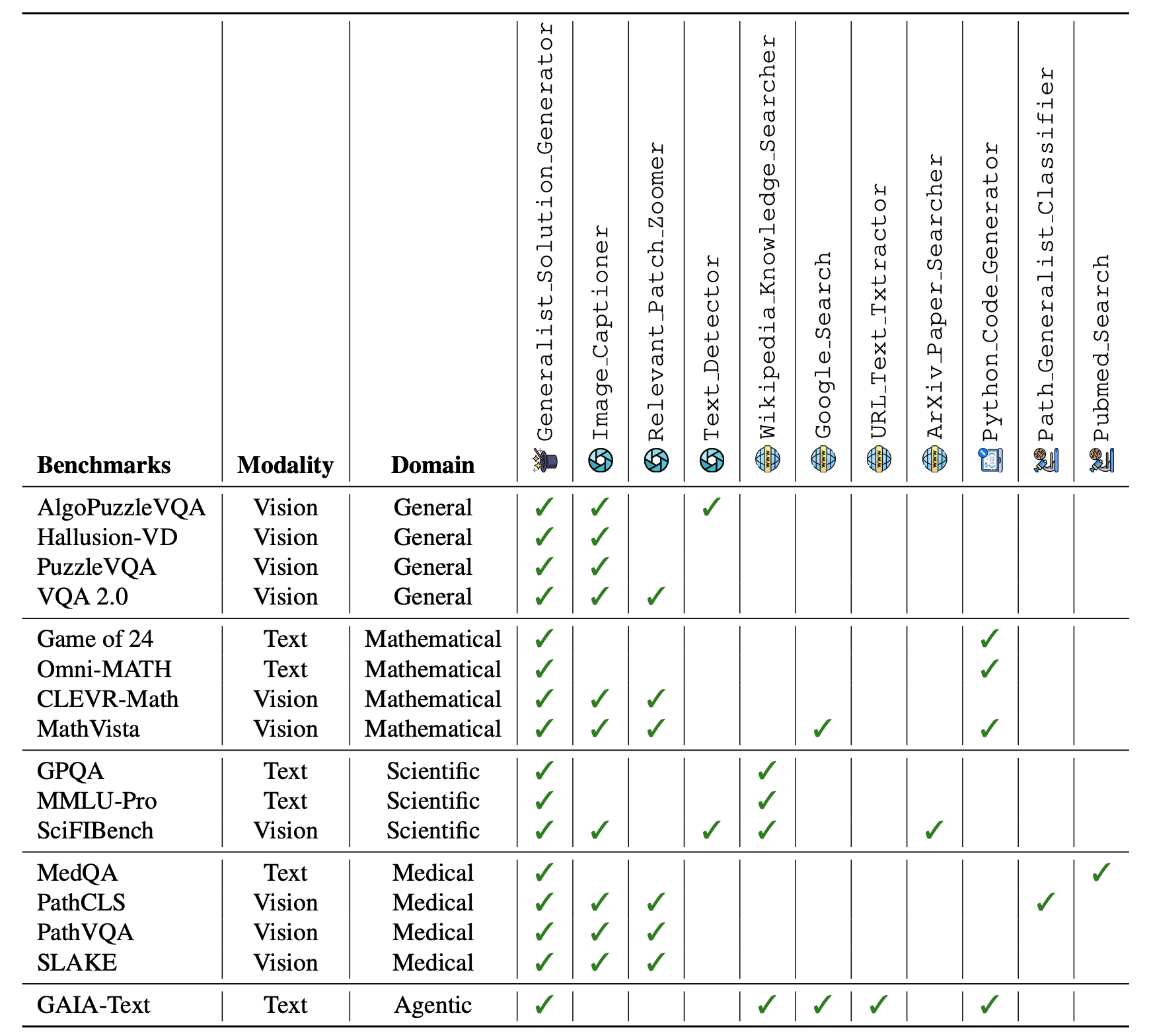
Optimized tool sets for each benchmark following our Algorithm. A ✓indicates that the tool is used for that benchmark.
@article{lu2025octotools,
author = {Lu, Pan and Chen, Bowen and Liu, Sheng and Thapa, Rahul and Boen, Joseph and Zou, James},
title = {OctoTools: An Agentic Framework with Extensible Tools for Complex Reasoning},
journal = {arXiv preprint arXiv:2502.11271},
year = {2025}
}
